PostgreSQL ON CONFLICT: The Ultimate Upsert Guide for 2026
Master PostgreSQL ON CONFLICT with this ultimate guide. Learn how to handle data conflicts with DO NOTHING and DO UPDATE for atomic, high-performance upserts.

At its core, PostgreSQL's ON CONFLICT is your go-to command for gracefully handling duplicate data. Instead of letting a "unique constraint violation" error crash your application, it gives you two powerful choices: either update the existing record (often called an "UPSERT") or simply ignore the new one. This one command is a cornerstone for building robust, high-performance applications.
What Is PostgreSQL ON CONFLICT And Why Is It Essential
Imagine your application is trying to add a new user, but their email—which has a UNIQUE constraint—is already in your users table. Without a plan, that INSERT statement would fail, and your application would throw an error. Before ON CONFLICT was a native feature, developers had to resort to clunky, risky logic on the application side to deal with this common scenario.
This old-school method usually involved first running a SELECT to see if the record existed. Depending on that result, you'd then follow up with a separate INSERT or UPDATE. Not only is this multi-step dance slower because of the extra round trips to the database, but it also opens a huge door for race conditions.
A race condition is what happens when two separate processes try to modify the same data at almost the same time. With a "check-then-insert" pattern, both processes might check for a user, find nothing, and then both try to insert. The second one to the finish line inevitably fails with an error.
The Atomic Solution to Data Integrity
The ON CONFLICT clause, first introduced in PostgreSQL 9.5, elegantly solves this problem right inside the database. It bundles the check and the resulting action into a single, indivisible—or atomic—operation. This atomicity is key, as it guarantees the action completes safely without any interference from other transactions happening at the same time.
By handling potential conflicts in one clean shot, ON CONFLICT delivers some serious benefits:
- Rock-Solid Data Integrity: It enforces your unique constraints at the database level, which is always the most reliable place to manage your data rules. No more accidental duplicates.
- Massive Performance Gains: It slashes database overhead by getting rid of those extra
SELECTqueries. For bulk imports or high-throughput systems, benchmarks have shown performance improvements of over 70% compared to application-level logic. - Cleaner, Simpler Code: It lets you rip out complex, error-prone conditional logic from your application. Your codebase becomes far more readable and much easier to maintain.
A Practical Analogy
Think of ON CONFLICT as a smart bouncer at a club with a guest list.
The old way was to have one person with a clipboard check the list, then radio another person inside to either add the new guest or find the existing one and update their drink tab. It's slow, and if two friends with the same name arrive at once, chaos ensues.
With ON CONFLICT, the bouncer handles it all in one swift move. If the person's name is on the list, they just update their status (last_seen = NOW()); if not, they're added instantly. That's the kind of efficient, error-free process ON CONFLICT brings to your database.
Dissecting The ON CONFLICT Syntax And Actions
Let's get into the nuts and bolts of the INSERT ... ON CONFLICT command. To really use it effectively, you need to get comfortable with its structure. The syntax is surprisingly straightforward, giving you direct control over what happens when your data runs into a duplicate.
At a high level, the statement looks like this:
INSERT INTO table_name (column_list)
VALUES (value_list)
ON CONFLICT (conflict_target) DO action;
The most important piece of this puzzle is the conflict_target. This is how you tell PostgreSQL what you consider a duplicate. It’s usually a column (or a few columns) that has a UNIQUE constraint or is a primary key. Without a unique index or constraint on the target, PostgreSQL won't know when a conflict occurs.
Think of it as a simple fork in the road for your incoming data.
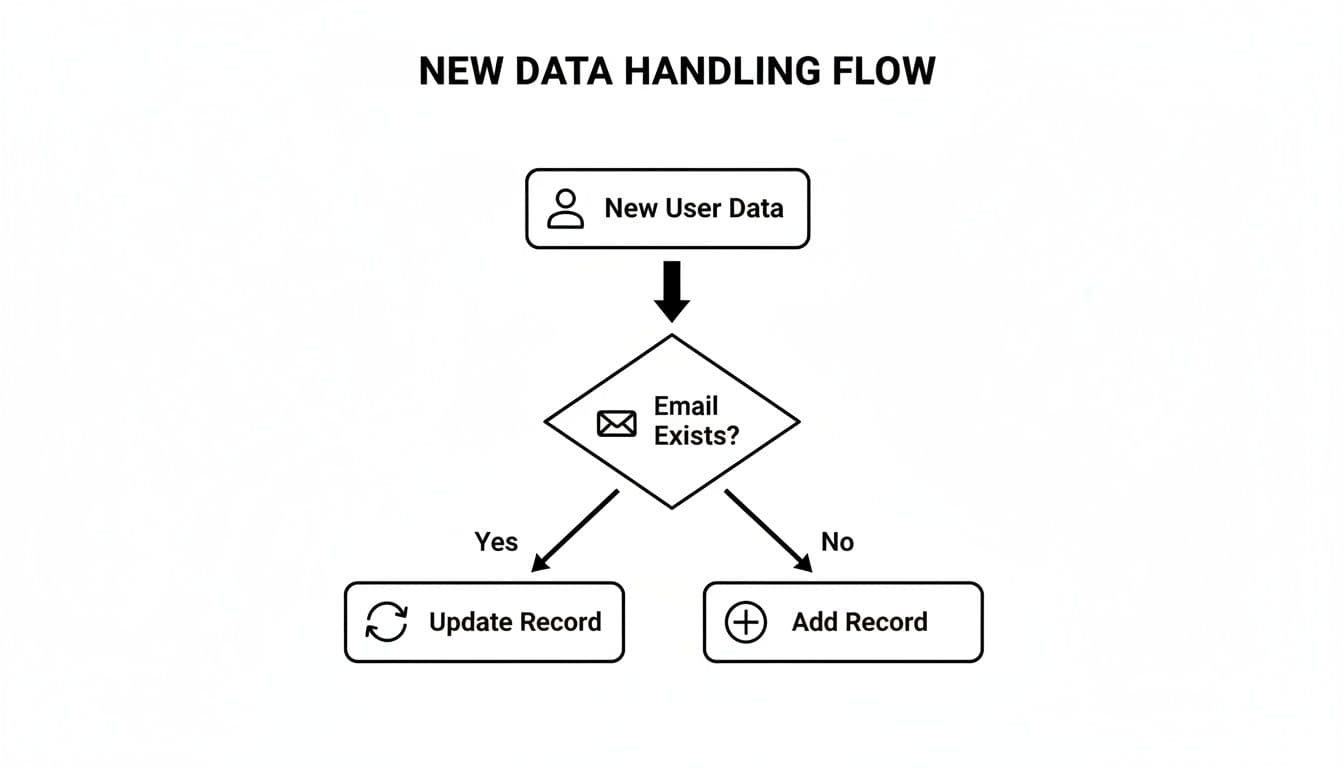
When new data arrives, the database checks if a record with that unique identifier (like an email) is already there. Based on the outcome, it either updates the existing record or inserts the new one.
The Two Core Actions
When PostgreSQL detects a clash on your conflict_target, you have two clear paths forward, specified by the DO clause.
-
DO NOTHING: This is your "ignore and move on" option. If the row you're trying to insert would create a duplicate, PostgreSQL just silently discards it. No errors, no fuss. The transaction just continues. -
DO UPDATE: This is the "merge" option, and it's what makes the UPSERT pattern so useful. If a conflict happens, you can run anUPDATEon the existing row that caused the problem.
Choosing the right conflict_target is crucial here. If you want to dive deeper, check out our guide on how to create indexes in SQL, since they are the foundation for this entire process.
DO NOTHING: The Silent Ignore
The DO NOTHING action is perfect when you just want to add new, unique data. Maybe you're logging unique user actions or importing a list where you only care about the entries that aren't already in your database. It's clean, efficient, and avoids any extra application logic.
Let's say you have an event_logs table with a unique constraint on event_id.
-- First, set up the table with a unique constraint
CREATE TABLE event_logs (
event_id VARCHAR(255) PRIMARY KEY,
description TEXT,
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- Try to insert a new event
INSERT INTO event_logs (event_id, description)
VALUES ('evt_123', 'User logged in')
ON CONFLICT (event_id) DO NOTHING;
If evt_123 is already in the table, this statement does absolutely nothing. If it’s new, the row gets inserted. Simple.
DO UPDATE: The Powerful Merge
This is where ON CONFLICT really earns its keep. DO UPDATE lets you specify exactly how to combine the new data with the record that's already there. The key to making this work is the special EXCLUDED table.
The
EXCLUDEDtable is a temporary reference to the row you tried to insert. You can grab values from its columns to decide how to update the conflicting row.
Let's look at a classic example: tracking user logins. We have a user_profiles table, and we want to update a user's last_login time and bump their login_count.
-- Set up a user table
CREATE TABLE user_profiles (
user_id SERIAL PRIMARY KEY,
email VARCHAR(255) UNIQUE NOT NULL,
last_login TIMESTAMPTZ,
login_count INT DEFAULT 0
);
-- Perform the upsert
INSERT INTO user_profiles (user_id, email, last_login, login_count)
VALUES (1, 'alex@example.com', NOW(), 1)
ON CONFLICT (email) DO UPDATE
SET
last_login = EXCLUDED.last_login,
login_count = user_profiles.login_count + 1;
Let's break down what's happening here:
- The
conflict_targetis theemailcolumn, which has aUNIQUEconstraint. - If a user with
alex@example.comalready exists, theDO UPDATEclause kicks in. last_loginis updated with the value from the new row we tried to insert (EXCLUDED.last_login).login_countis incremented by taking the existing value (user_profiles.login_count) and adding 1. This atomic operation prevents race conditions.
Real-World ON CONFLICT Examples
Alright, enough with the theory. Let's get practical and look at how you can use ON CONFLICT to solve real-world problems. This is where the syntax we've covered turns into powerful, everyday solutions.
Since INSERT ... ON CONFLICT landed in PostgreSQL, it has become a go-to tool for developers. The performance difference is staggering—benchmarks show a native ON CONFLICT can run a million upserts in just 14 seconds. Trying to do the same thing with application-level code takes around 47 seconds, meaning you get a 70% speed boost by doing it the right way. You can see the full benchmark breakdown on prisma.io if you're curious.
Here are a few common scenarios where ON CONFLICT really shines.
Syncing Records From A CSV Import
One of the most common jobs we have as developers is keeping our database in sync with an external file, like a daily CSV import of product inventory. You want to insert the new products and update the existing ones, all in a single, clean operation.
The Problem: You have a products table and a new CSV file containing the latest product names and prices. You need to add the new products and refresh the data for the old ones without your script crashing on a duplicate key error.
The Solution: Let's assume your table is set up and you're using a tool like psql's \copy or a server-side COPY command to load data into a temporary table first. From there, you can upsert into your main products table.
-- 1. Create the products table
CREATE TABLE products (
product_id INT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
price DECIMAL(10, 2),
updated_at TIMESTAMPTZ
);
-- 2. Create a temporary table for the CSV data
CREATE TEMP TABLE products_staging (LIKE products);
-- 3. (Assume you load your CSV into products_staging here)
-- Example: \copy products_staging from 'products.csv' with (format csv, header true)
-- 4. Upsert from the staging table to the final table
INSERT INTO products (product_id, name, price, updated_at)
SELECT product_id, name, price, NOW() FROM products_staging
ON CONFLICT (product_id) DO UPDATE
SET
name = EXCLUDED.name,
price = EXCLUDED.price,
updated_at = EXCLUDED.updated_at;
With one command, you've made your data sync process bulletproof. This pattern is great for data ingestion. If you work with CSVs often, our guide on importing CSV data into PostgreSQL covers this and other helpful techniques.
Tracking User Activity With A Last Seen Timestamp
Here’s another classic: you want to keep track of the last time a user was active in your application. This usually means updating a timestamp every time they make a request.
The Problem: You have a users table and need to update a last_seen_at column. If it's a known user, you update the timestamp. If it's a brand new user, you create their record.
Why this matters: Using
ON CONFLICThere makes the update atomic. You avoid a separateSELECTcheck to see if the user exists, which simplifies your code and prevents race conditions where two requests might try to insert the same user at once.
The Solution: We'll target a unique identifier like user_id or email. If a conflict happens, the DO UPDATE clause kicks in and simply updates the last_seen_at column with the new timestamp.
INSERT INTO users (user_id, email, last_seen_at)
VALUES (42, 'jane.doe@example.com', NOW())
ON CONFLICT (user_id) DO UPDATE
SET
last_seen_at = EXCLUDED.last_seen_at;
This is simple, clean, and incredibly effective for maintaining accurate activity logs in a busy system.
Implementing An Atomic Counter
Counters are everywhere in analytics—page views, download counts, likes, you name it. The old "read, increment, then write back" method is a classic recipe for disaster in a concurrent system, leading to lost counts and inaccurate data.
The Problem: You need to increment a view_count on an articles table every time someone views a page. This operation has to be atomic to ensure every single view is counted, even under heavy traffic.
The Solution: This is where ON CONFLICT truly shows its power for concurrency. You optimistically try to INSERT a new record with a view_count of 1. If the record already exists (the normal case), the DO UPDATE clause takes over and increments the existing value.
-- First, set up the table
CREATE TABLE article_views (
article_id INT PRIMARY KEY,
view_count BIGINT DEFAULT 1
);
-- Then, run this query for each page view
INSERT INTO article_views (article_id, view_count)
VALUES (789, 1)
ON CONFLICT (article_id) DO UPDATE
SET
view_count = article_views.view_count + 1;
Notice how we reference article_views.view_count in the UPDATE part. This refers to the current value in the row we conflicted with. This approach completely sidesteps any race condition, guaranteeing every increment is safely applied.
Quick-Reference Recipes
To make things even easier, here’s a handy table that summarizes these patterns and a few others. Think of it as a cheat sheet for your next project.
| ON CONFLICT Use Case Recipes |
| :--- | :--- | :--- |
| Use Case | Problem | SQL Solution Snippet |
| Syncing Data | Insert new records or update existing ones from a data source like a CSV. | ON CONFLICT (unique_id) DO UPDATE SET col1 = EXCLUDED.col1, col2 = EXCLUDED.col2; |
| Atomic Counter | Increment a number (e.g., view count) without race conditions. | ON CONFLICT (article_id) DO UPDATE SET count = a_views.count + 1; |
| "Last Seen" Timestamp | Record the latest activity time for a user or entity. | ON CONFLICT (user_id) DO UPDATE SET last_seen = NOW(); |
| "First Seen" Timestamp | Record only the initial creation time and ignore subsequent attempts. | ON CONFLICT (user_id) DO NOTHING; |
| Set Leader | In a group of records, designate one as the leader and demote the old one if a new leader is inserted. | ON CONFLICT (group_id) WHERE is_leader IS TRUE DO UPDATE SET is_leader = FALSE; |
These recipes cover some of the most frequent challenges you'll face. By keeping them in your back pocket, you can write more robust and efficient SQL with confidence.
Unlocking Performance and Concurrency Benefits
So, why is ON CONFLICT so much faster and safer than trying to handle duplicates in your application code? The secret lies in its atomicity. Instead of performing a clumsy, multi-step dance of SELECT then INSERT or UPDATE, ON CONFLICT executes the entire check-and-act logic in a single, indivisible step right inside the database.
This brings immediate and massive performance gains. Every round trip your application makes to the database adds network latency. By collapsing what would have been two or three separate queries into just one, you slash that overhead. The result is a snappier application and happier users.
Eliminating Race Conditions
The most crucial benefit of atomicity, though, is how it completely sidesteps race conditions. Imagine two requests hitting your server at the exact same millisecond, both trying to add the same new user. With a manual "check-then-insert" pattern, both could check for the record, see it doesn't exist, and then both try to INSERT it. The second one to arrive will inevitably crash with a unique constraint violation.
ON CONFLICT solves this by design. Because the entire operation is atomic, PostgreSQL ensures that only one process can successfully complete the action for a given row at a time. The database handles all the tricky internal locking, guaranteeing data integrity without you having to write complex, error-prone code in your application.
This atomic nature is what transforms
ON CONFLICTfrom a mere convenience into a cornerstone of robust system design. It delivers predictable behavior in high-throughput environments where many clients are writing data all at once.
Minimizing Locking and Boosting Concurrency
In a busy database, excessive locking can bring performance to a crawl. The old-school SELECT-then-UPDATE approach often requires taking heavy-handed locks on the table just to prevent the race conditions we talked about. These locks can block other writers, creating a serious bottleneck.
ON CONFLICT is far more surgical. It uses a special, highly efficient lock that is both fine-grained and short-lived. This minimizes the impact on other concurrent operations, making it a perfect fit for high-concurrency workloads like:
- Tracking events for real-time analytics
- Ingesting and synchronizing bulk data sets
- Updating status from thousands of IoT devices
By reducing lock contention, ON CONFLICT allows your database to handle more simultaneous writes, significantly improving your system's overall throughput. To really get why this matters, it helps to understand what a database transaction is and the safety guarantees it provides.
A Critical Tool for Database Replication
The benefits of ON CONFLICT even extend into high-availability setups. In a primary-replica architecture, the replica server is constantly replaying write operations from the primary. Occasionally, queries running on the replica (like a long-running analytics job) can clash with these incoming changes, causing replication to stall or even fail.
This is another area where INSERT ... ON CONFLICT truly shines. It can automatically resolve certain kinds of conflicts right on the standby server without any manual intervention, ensuring replication keeps flowing smoothly. You can even keep an eye on this using PostgreSQL's pg_stat_database_conflicts view. Given that Postgres powers a significant portion of production databases worldwide, keeping replication healthy is non-negotiable, and ON CONFLICT is a key tool in that fight. You can discover more insights about PostgreSQL's monitoring stats directly from the official docs.
The Evolution Of Upsert In PostgreSQL
It's easy to take ON CONFLICT for granted now, but to really get why it’s so important, you have to remember what life was like before it arrived. PostgreSQL version 9.5 was a game-changer, because before its release, handling something as basic as a duplicate record was a messy and often dangerous affair.
Developers had to jump through hoops, building their own logic to prevent duplicate entries. These weren't just clunky; they were ticking time bombs, riddled with subtle bugs that could easily corrupt data when multiple transactions were happening at once.
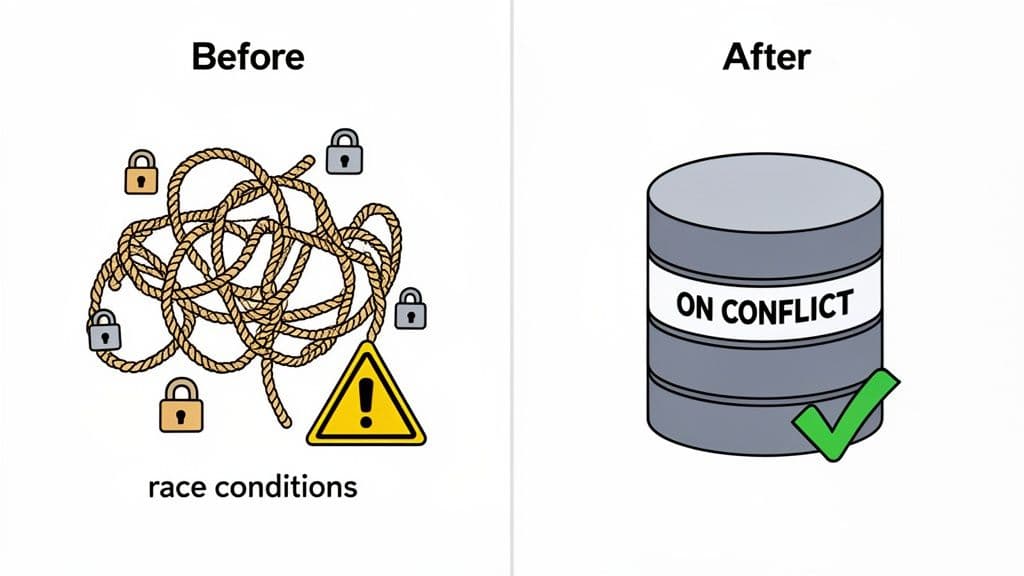
The Era Before Native Upsert
Back then, you had two main, not-so-great options for building your own upsert functionality. Each came with its own set of headaches.
A very common technique was the "check-then-act" pattern, handled right in the application code. You'd first run a SELECT to see if a row already existed. If it didn't, you'd INSERT. If it did, you'd UPDATE. The problem? This approach was slow, requiring multiple trips to the database. More importantly, it left a huge gap for race conditions to sneak in between the check and the action.
Another path was to write complex functions in PL/pgSQL. The idea was to wrap an INSERT in a BEGIN...EXCEPTION block and catch the unique_violation error if it happened. While this moved the logic closer to the data, it was verbose and still not as fast as a native command. In fact, some benchmarks show that a simple ON CONFLICT DO NOTHING can slash insertion latency by up to 73% compared to a try-catch block. You can dig into the numbers in this full analysis of PostgreSQL conflict performance.
In the most extreme cases, some developers even resorted to manually using advisory locks to serialize access to specific rows. This was a fragile, high-overhead workaround that was incredibly difficult to implement correctly and a nightmare to maintain.
A Major Leap Forward
When INSERT ... ON CONFLICT landed in PostgreSQL 9.5, it was a breath of fresh air. It elegantly solved all these problems with a single, atomic command that was cleaner, safer, and faster.
- Simplicity: It replaced sprawling, multi-line functions and fragile application logic with one declarative line of SQL.
- Safety: Because the entire operation is atomic, it completely slammed the door on the race conditions that plagued the old "check-then-act" methods.
- Performance: It cut down database overhead significantly by handling the entire insert-or-update decision in one efficient, server-side operation.
This single feature finally brought PostgreSQL up to speed with other major databases that had offered similar "upsert" commands for years. It was more than a nice-to-have; it was a crucial development that helped fuel PostgreSQL's adoption for modern, high-concurrency applications where data integrity is non-negotiable. It truly marked the end of the dark ages of manual conflict handling.
Answering Your Top Questions About PostgreSQL ON CONFLICT
As you start using INSERT ... ON CONFLICT in your own projects, you'll inevitably run into a few tricky spots. It's a powerful feature, and while it's mostly straightforward, some of its nuances can trip up even seasoned developers. Let's walk through the most common questions to help you sidestep those pitfalls and write cleaner, more reliable queries.
This isn't just a list of facts; it’s practical advice to clear up confusion around how ON CONFLICT plays with indexes, triggers, and other parts of your database.
What’s the Difference Between ON CONFLICT and MERGE?
This is a huge point of confusion, especially for developers coming from database systems like SQL Server or Oracle. While both commands can handle "upsert" logic, they’re built for very different purposes and operate in fundamentally different ways.
Think of ON CONFLICT as a precision tool. It’s a PostgreSQL-specific feature bolted directly onto the INSERT statement. Its sole purpose is to cleanly handle what happens when a new row would violate a unique constraint. It's concise, highly optimized for this one job, and famously safe from concurrency race conditions.
The MERGE command, on the other hand, is part of the broader SQL standard (introduced in PostgreSQL 15). It’s more like a versatile multi-tool. MERGE isn't just about inserts; it can perform a combination of inserts, updates, or even deletes on a target table by comparing it against a source. This makes it more powerful but also significantly more verbose and complex.
Here's a quick breakdown:
| Feature | INSERT ... ON CONFLICT | MERGE |
|---|---|---|
| Origin | PostgreSQL-specific (v9.5+) | SQL Standard (PostgreSQL v15+) |
| Primary Action | INSERT with a conflict resolution clause | Joins a source and target, then acts |
| Supported Actions | DO NOTHING or DO UPDATE | WHEN MATCHED THEN UPDATE/DELETE, WHEN NOT MATCHED THEN INSERT |
| Complexity | Simple, direct syntax | More complex and verbose |
| Concurrency | Highly resistant to race conditions | Can be prone to race conditions in some implementations |
Actionable Insight: For a simple upsert based on a unique key in PostgreSQL, ON CONFLICT is almost always the better, safer, and faster choice. Use MERGE for complex ETL scenarios where you need to orchestrate conditional updates, inserts, and deletes between two tables in a single operation.
Can You Use ON CONFLICT With Partial Unique Indexes?
Absolutely, and this is where you can unlock some powerful, fine-grained control over your data integrity. A partial unique index is a fantastic feature that only enforces uniqueness on a subset of rows—specifically, those that match its WHERE clause.
For ON CONFLICT to recognize and use a partial index, your conflict_target has to be a perfect match. That means you need to specify not only the indexed columns but also the exact same WHERE condition used in the index definition.
Actionable Example: Let's say you have a tasks table and want to enforce a rule that a user can only have one "active" task at any given time.
-- 1. Create a partial unique index on active tasks.
CREATE UNIQUE INDEX idx_unique_active_task_per_user
ON tasks (user_id)
WHERE status = 'active';
-- 2. Use that exact same WHERE clause in your ON CONFLICT statement.
INSERT INTO tasks (user_id, description, status)
VALUES (123, 'Write weekly report', 'active')
ON CONFLICT (user_id) WHERE status = 'active'
DO UPDATE SET
description = 'UPDATED: ' || EXCLUDED.description;
If you forget the WHERE status = 'active' part in the ON CONFLICT clause, PostgreSQL won't see the connection to your partial index, and the conflict won't trigger as you expect.
How Does ON CONFLICT Interact With Triggers?
This is a critical detail. Understanding the firing order of triggers during an ON CONFLICT operation will save you from a world of head-scratching and unexpected behavior. The sequence is logical once you see it laid out.
-
BEFORE INSERTtriggers always fire. PostgreSQL always attempts theINSERTfirst. This means anyBEFORE INSERTtriggers on the table will run for every row you're trying to add, regardless of whether a conflict is ultimately found. -
AFTER INSERTtriggers only fire if the row is actually inserted. If there's no conflict and the new row is successfully added, yourAFTER INSERTtriggers will run just like they normally would. -
If a conflict triggers an
UPDATE, theUPDATEtriggers fire instead. Here's the pivot. When a conflict is detected and yourDO UPDATEclause kicks in, theAFTER INSERTtriggers are skipped entirely. Instead, theBEFORE UPDATEandAFTER UPDATEtriggers are fired for the existing row that was just modified.
Actionable Insight: A single INSERT ... ON CONFLICT ... DO UPDATE statement will never fire both AFTER INSERT and AFTER UPDATE triggers for the same row. It’s strictly one or the other. Be mindful of this when designing trigger logic for tables that use upserts.
How Do You Get The Final Row After An Upsert?
This is a very common requirement. After an upsert, you usually need the final state of the row, whether it was newly inserted or just updated. Thankfully, PostgreSQL gives us a beautifully simple way to do this: the RETURNING clause.
Simply add RETURNING * (or a specific list of columns) to the end of your ON CONFLICT statement. It works perfectly with both DO NOTHING and DO UPDATE paths.
Actionable Example: Imagine you're updating a user's login count and immediately need their new total count in your application.
INSERT INTO users (id, email, login_count)
VALUES (1, 'test@example.com', 1)
ON CONFLICT (id) DO UPDATE
SET login_count = users.login_count + 1
RETURNING id, email, login_count, last_login;
- If user
id = 1doesn't exist, a new row is inserted.RETURNINGwill return that new row, withlogin_countset to 1. - If user
id = 1already exists, thelogin_countis incremented.RETURNINGwill return the updated row, showing its newlogin_count.
This little clause lets you get the final state of the record in a single, atomic database round-trip, completely eliminating the need for a follow-up SELECT query.
Managing your database doesn't have to be a chore. TableOne is a modern, cross-platform database tool built to make your everyday data work fast and predictable. With a simple one-time license, you get powerful features like schema comparison, CSV import, and a clean interface for PostgreSQL, MySQL, and SQLite without the clutter or subscription fees. Learn more and start your free trial at TableOne.


